Written by

Over the past 6 years, we’ve been taking on the challenge of leveraging technology to make financial data extraction easier. Now, we produce the market’s premium fundamental credit data sets. Here’s how we do it.
Building a credit model is a fundamental component of forming a credit view. For decades, credit analysts have been performing this task manually, and it’s a slow, inconsistent and error-prone process.
Today, we deliver the market’s fastest, and most accurate credit models. Naturally, we get a lot of questions from clients about how our technology is able to do this with such accuracy, speed and scale. In this blog, we’ll explain why we developed proprietary technology specifically for financial data extraction, how it’s enabled us to revolutionize the traditional credit modeling process, and provide a step-by-step guide on how we deliver the market’s premium fundamental credit data.
Why is financial data extraction so difficult?
For credit analysts, financial data is everything. It’s how they build credit models and form their view on an issuer in the hope of identifying a valuable investment opportunity. But that data is not always easily accessible. In most cases, earnings data is locked away in financial reports that are distributed as PDF documents. And when it comes to any kind of data extraction, PDFs are less than ideal.
Why? To answer that question, it helps to understand what a PDF actually is. Short for Portable Document Format, a PDF is a form of image data - a series of instructions that describe the appearance of a document. When a source document (eg. MS Word) is converted into a PDF, the words and numbers are converted into primitive drawing instructions which are then rendered as pixels when displayed or printed. The “structural function” of those words - table headers, column headers, row labels etc - is all lost.
This is the common problem that plagues any kind of data extraction from PDFs. When data is lost, the only way to reproduce the values and formatting is by doing it manually. If you’ve ever tried to copy and paste a table out of a PDF, you know exactly what we’re talking about.
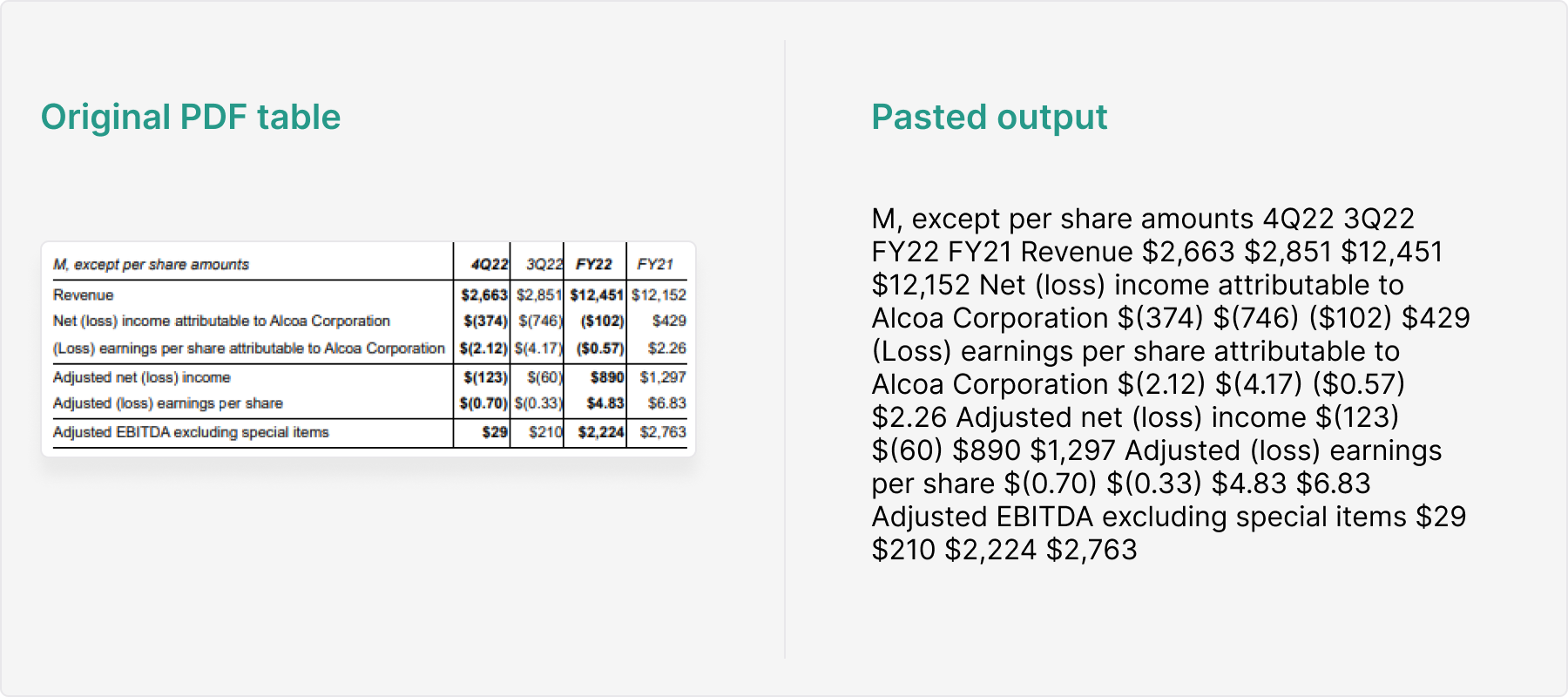
The human challenges of financial data extraction
For our audience, the two most pressing challenges credit analysts face when building a credit model are speed and accuracy. The faster they work, the more error-prone the process becomes. The more diligent they are, the slower the process becomes.
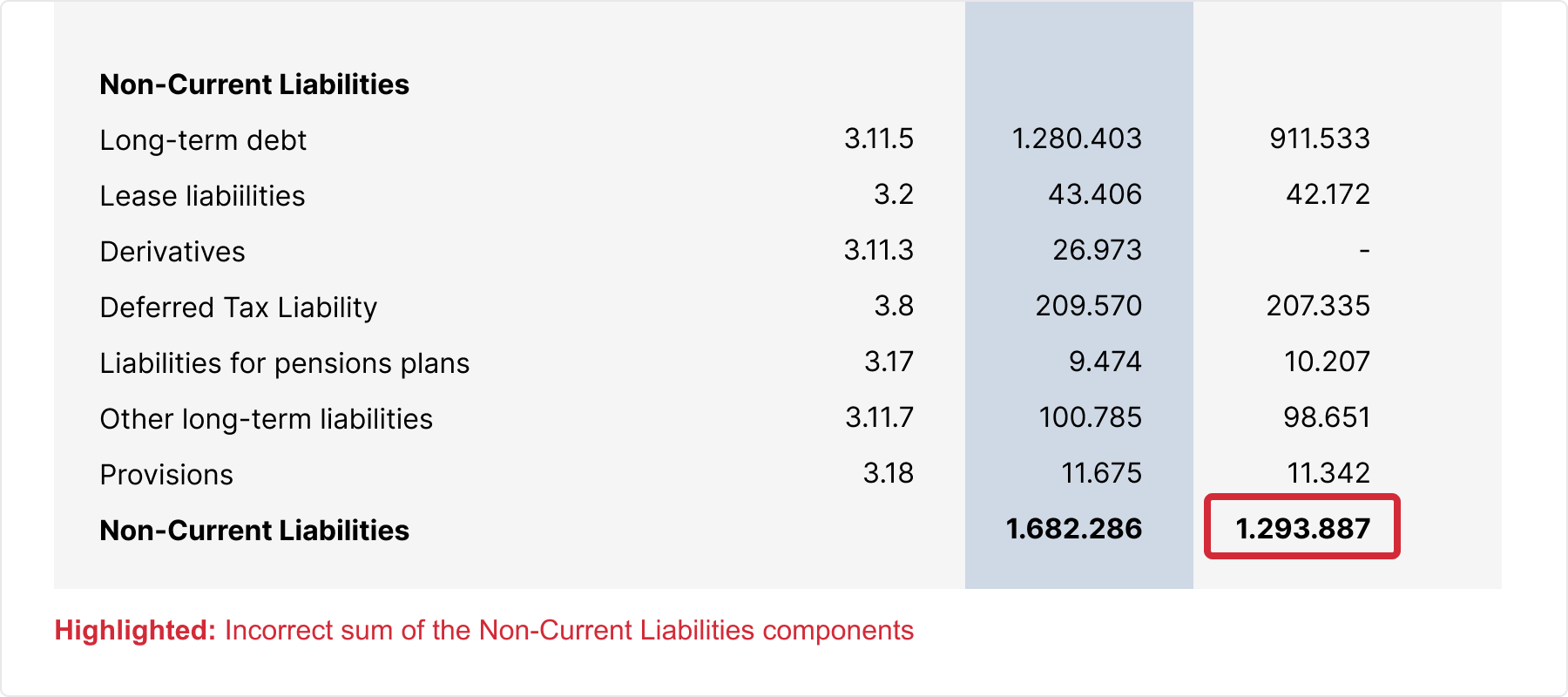
Additionally, not only are analysts susceptible to making mistakes when transposing numbers from a financial report into a spreadsheet model, but the source document written by another human also has the potential to contain errors, too (see example below). Whilst humans can spot and fix a single error in isolation, we can’t repeat that process at speed, across multiple documents of varied lengths to a high degree of accuracy.
All of this creates a high risk of human error in the final output. That's where technology can help.
Why use technology for financial data extraction?
Though this is not an exhaustive list of the challenges in financial data extraction, it makes clear the difficulties involved. The volume of data, the inconsistencies contained and the format in which it is distributed make it a very manual, time-consuming and error-prone process. And, as we’ve written previously, that’s exactly what credit analysts have been doing for decades. It’s an inefficient process to say the least.
At Cognitive Credit, we’ve always believed that technology can solve this problem. Where humans are good at doing something once, computers are excellent at doing something over and over again at speed and accurately. But, although there are many generic PDF extraction tools available in consumer markets, none of these solutions are robust enough to deal with the unique complexities in financial data extraction described above. Why? Because they are simply not accurate enough, and are unable to account for the specific meanings of data in financial reports.
That’s why we’ve built a proprietary solution tailored specifically to earnings data and credit market participants.
Step-by-step: How we extract financial data
Building a detailed financial model for a single company requires accurate selection, extraction and transcription of data from multiple documents, over thousands of pages. In developing our solution, we’ve had to solve the challenges associated with producing a credit model directly from a series of financial statement PDFs in an automated fashion. But we’ve also built the technology in a way that directly addresses the challenges human analysts face when manually building a credit model - namely accuracy, speed, presentation and transparency.
Here’s our step-by-step guide of how we combine machine-reading, image recognition, traditional computer science and more into a fast, accurate and reliable financial data extraction process.
1 / We find the appropriate company financial statements
Before a credit model can be built, our team finds the data required to build it. This data comes in the form of financial reports, presentations, prospectuses and more. Additionally, our team will lay the groundwork for the credit model by preparing some basic facts about the issuer - key details such as their reporting calendar, ticker code, industry and sector etc.
Once the preparation is completed, we’re ready to begin extracting the financial data.

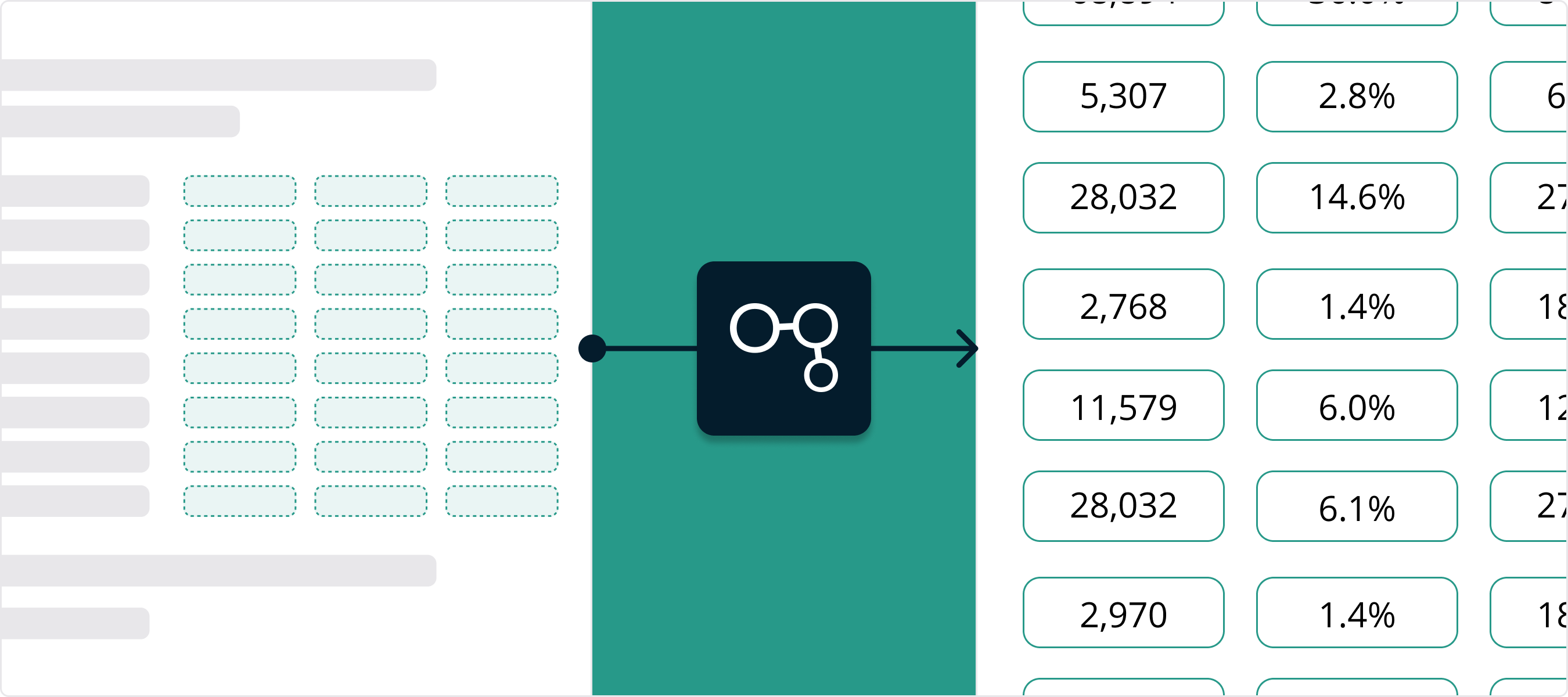
2 / Every table and every value, in every document
As the documents are fed into our technology, image recognition searches every page in every statement for tables containing values it identifies as relevant to the credit model. Once identified, the technology automatically selects and transcribes any value contained in those tables and classifies each one based on knowledge of relevant accounting concepts. These values are then arranged into a time-series based on the reporting calendar indicated in step one.
How does our technology know which tables and values are relevant for a credit model, you might ask? Having scanned millions of pages from financial documents over time, our technology has been trained through trial, error and instruction on what data should automatically be extracted and how it should be classified - Income Statement, Balance Sheet, Cashflow, etc. Over time, we refine and retrain the technology to cover additional cases leading to a higher level accuracy over a broader range of documents.
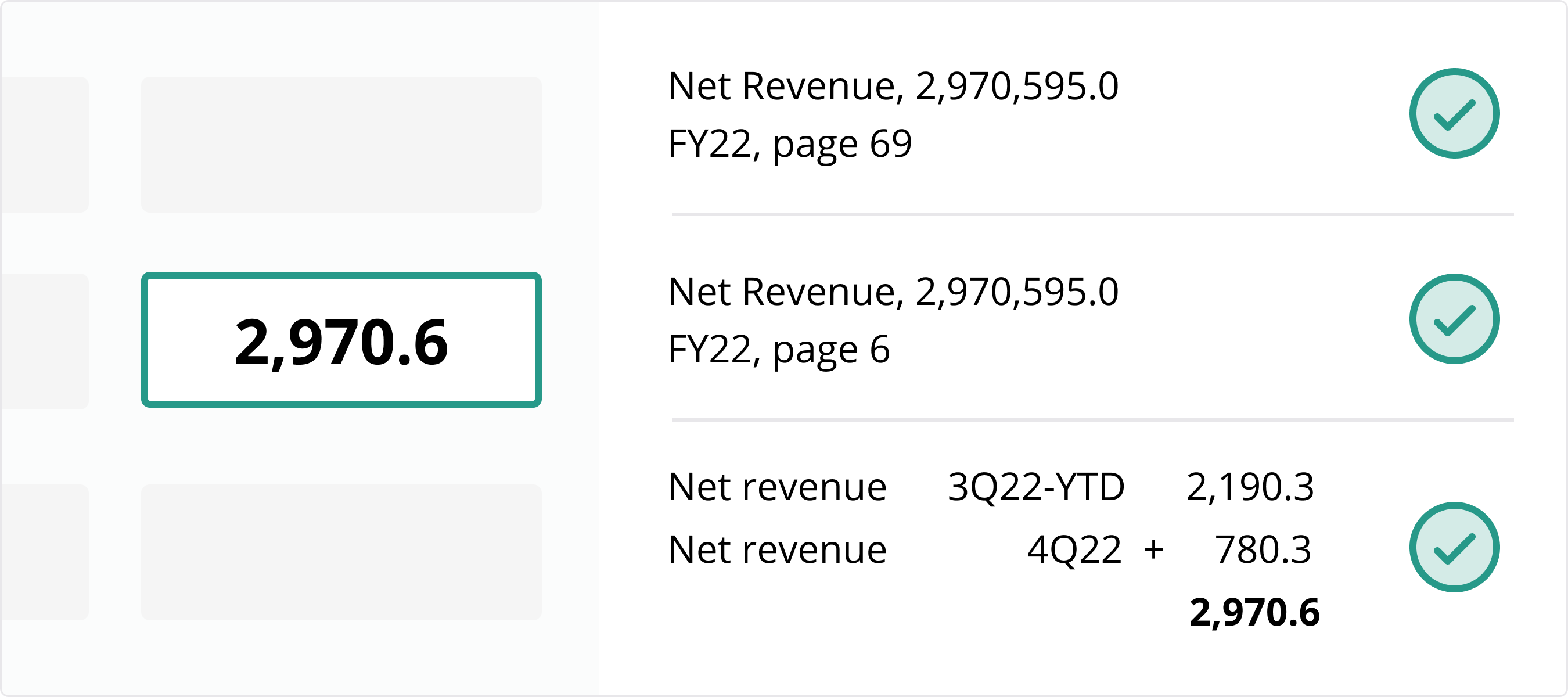
3 / Data is programmatically cross-checked
Once all values have been extracted and classified, our technology then cross-checks all values for any discrepancies. It does this by verifying the arithmetical relationships between related data points (i.e. does A + B really equal C?) and by comparing values that have been reported multiple times (i.e. does A on Page 6 equal A on Page 69?).
When discrepancies are found, our technology consults an established list of possible reasons for each one. Is it a human miscalculation? Is it a restated value? Is it simply human error? If a valid reason is found, a correction is automatically issued and logged for auditing purposes. For discrepancies that can’t be resolved, the value is automatically flagged for our team during quality-checking.
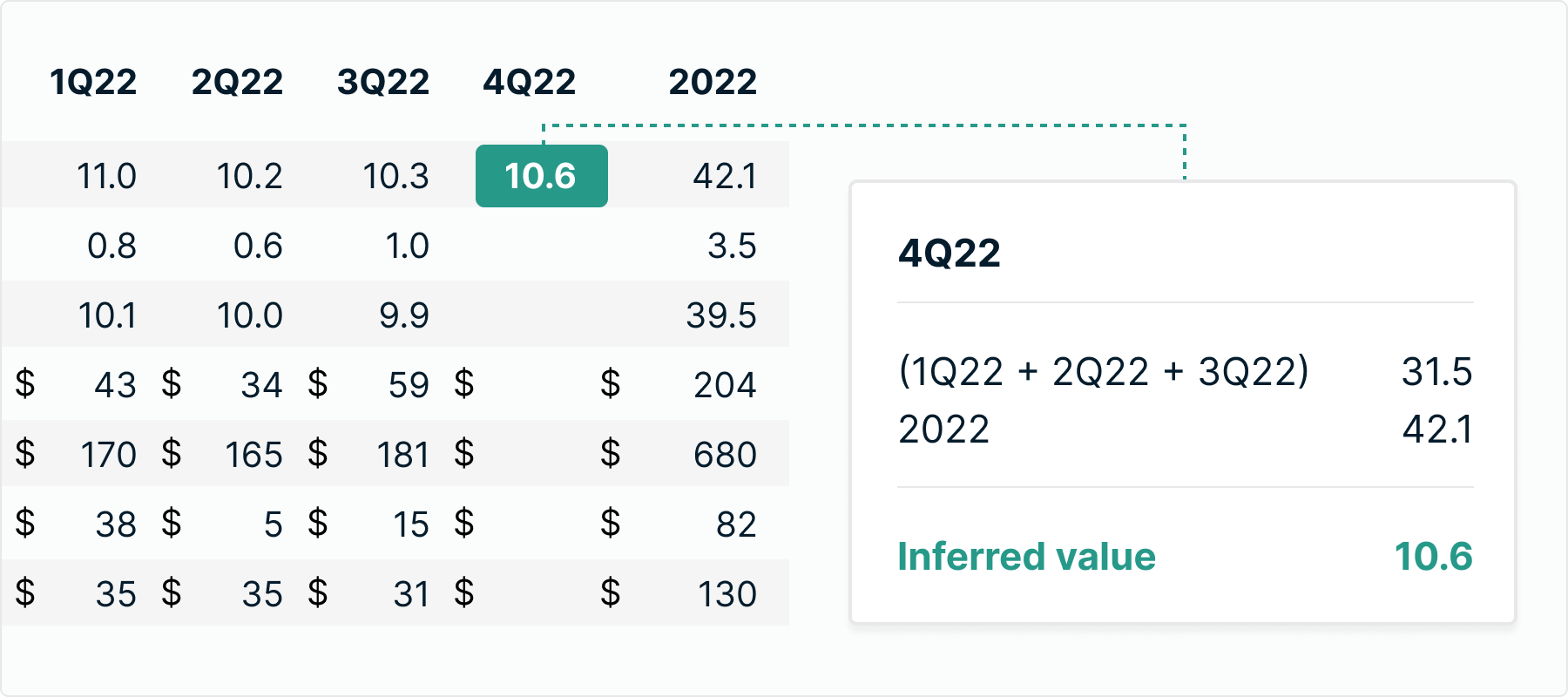
4 / We enrich the data with inferred values
Often, financial documents will have missing or not-stated values that can leave gaps in the dataset. As well as providing accurate data, we strive to deliver the most complete data, too. That’s why our technology is able to infer missing values based on known accounting relationships.
For example, fourth quarter figures may not be stated in a company report. But if we have historically extracted figures for the first three quarters as well as the end of year figure, our technology can infer the fourth quarter figures as the difference between the two.
This process takes place programmatically across the entire dataset in minutes. It allows us to produce a complete set of metrics for many aspects of an issuer’s business that may not have been explicitly stated in the original report - and deliver a truly comprehensive financial model.
5 / The post-processing, human quality check
Once all this has been completed, the technology outputs a finished credit model and a list of any unresolved discrepancies back to our senior credit analysts.
At this point, our team performs a check of the model and identifies any lingering discrepancies. Once diagnosed, the team provides the technology with additional instructions that enables it to solve these discrepancies independently going forward. We then instruct the technology to build the model again based on these new settings, and repeat this process until our team is happy with the output.
It’s important to note that we never make any manual changes to the models delivered by our technology - that would defeat the point of using technology to build credit models in the first place. That’s why, via instructions and refinements, we guide the technology on how best to process and structure the financial data it has extracted.
Every time new instructions are added, the technology becomes smarter and able to handle more complex discrepancies independently. In turn, this leads to faster document processing and shorter turnaround times.
End result: Faster, accurate, automated credit modeling
Whether it’s responding to a new coverage request or the publication of reports during earnings seasons, our clients are consistently impressed at the speed with which we produce accurate data. Here’s how the typical timings break down:
- Client requests for new credit models are turned around in 24 hours
- When a new issuer comes to market we publish a Prospectus-based model in 6 hours
- We update credit models for new earnings data in under 15 minutes
And unlike a human credit analyst, our technology processes multiple earnings reports in parallel. So, when 20 companies publish new earnings reports at the same time, you get a model for each one within the same 15 minute period.
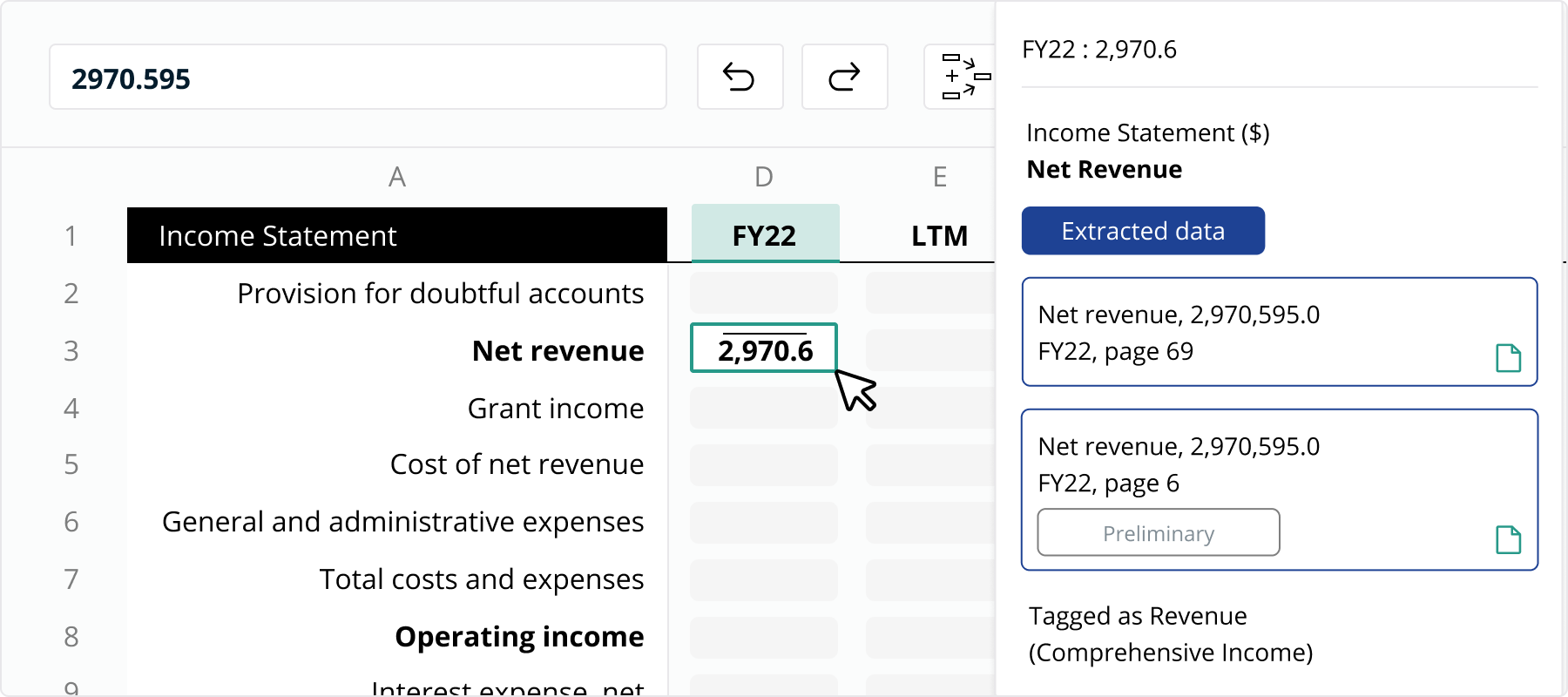
Furthermore, by automating this entire process - extraction, classification, validation, enrichment and discrepancy checking - every single value in our credit models have detailed audit trails and can be traced back to source documents easily. In fact, when using our web application, our audit tab gives you all of this information in a single click (see image below).
Automate your credit modeling today
In short, our financial data extraction technology not only delivers superior accuracy in a shorter time, but also full transparency on where each value has come from. Credit modeling no longer needs to take hours or days of time - it can be done in minutes. And, more importantly, it can be scaled - meaning your market coverage doesn’t have to be limited.
Whatever your coverage size, our financial data extraction solution can help you cover more credits, faster. You’ll never be caught out by a deluge of new reporting during earnings season, and you’ll always have an up-to-date credit model on which to form your view.
To see our models first-hand, just request a demo today.
Or, if you’d like to ask a question about our financial data extraction technology, get in touch anytime.
This post features contributions from Guy Hindell, Richard Wheeldon and Sudha Sathiaseelan
You might also like
 9 min read
9 min read
 4 min read
4 min read
